Technical
Architecture
PrintGrid has been designed to be source-agnostic, so in addition the the headless PrintGrid API, its accompanying Design-UI, as well as the PDF renderers, there are adapters for every flavor of data source system (called $PIM here for short).
The default use case is that the $PIM triggers the entire stack by requesting a PDF of certain article(s), receives a processing ticket in return, with which it can then poll for the completed PDF, and then finally download said PDF.
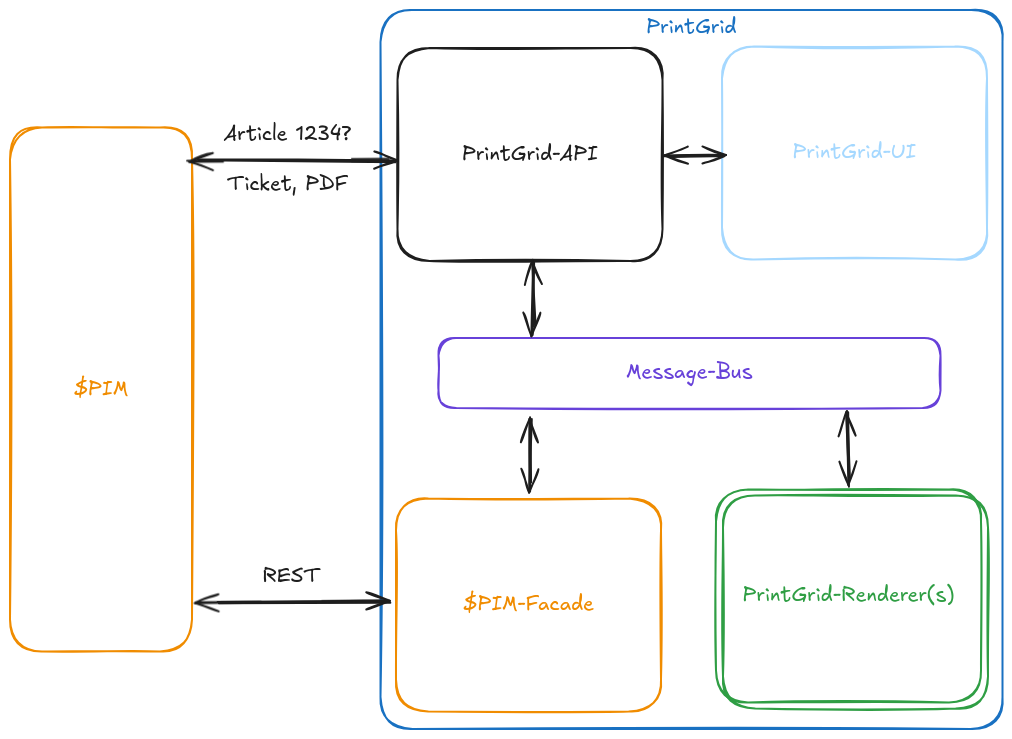
In the back-end, the API coordinates the request, first to fetch the data from $PIM (through a configured facade), and then sending it off to a render engine, which transforms the data to HTML and then in turn to a PDF.
The intermediary HTML facilitates easy customizing of your particular layout, as many people "speak" HTML/CSS.
API
See the Swagger-Docs - as a third party integrator, you only need to look at render-endpoint, 1. /query 2. /status and 3. /pdf
© brix Solutions AG